本文共 6580 字,大约阅读时间需要 21 分钟。
转载请注明出处:
引言
JDK1.4中引入了NIO,即New IO,目的在于提高IO速度。特别注意JavaNIO不全然是非堵塞式IO(No-Blocking IO),由于当中部分通道(如FileChannel)仅仅能运行在堵塞模式下,而其它的通道能够在堵塞式和非堵塞式之间进行选择。
虽然这样。我们还是习惯将Java NIO看作是非堵塞式IO,而前面介绍的面向流(字节/字符)的IO类库则是堵塞的,它们在数据从介质->OS内核这个阶段须要应用程序堵塞等待完毕,具体来看,面向流的IO和非堵塞式IO的差别例如以下:
| IO | NIO |
| 面向流(Stream oriented) | 面向缓冲区(Buffer oriented) |
| 堵塞式(Blocking IO) | 非堵塞式(Non blocking IO) |
| 无 | 选择器(Selectors) |
可是千万记住,两者没有孰优孰劣。NIO是java io的拓展,依据不同的场景。两者各实用处。
面向流与面向缓冲
Java NIO和IO之间第一个最大的差别是,IO是面向流的,NIO是面向缓冲区的。 JavaIO面向流意味着每次从流中读一个或多个字节,直至读取全部字节,它们没有被缓存在不论什么地方。此外,它不能前后移动流中的数据。假设须要前后移动从流中读取的数据,须要先将它缓存到一个缓冲区。
Java NIO的缓冲导向方法略有不同。
数据读取到一个它稍后处理的缓冲区,须要时可在缓冲区中前后移动。这就添加了处理过程中的灵活性。可是,还须要检查是否该缓冲区中包括全部您须要处理的数据。并且。需确保当很多其它的数据读入缓冲区时,不要覆盖缓冲区里尚未处理的数据。
堵塞与非堵塞IO
Java IO的各种流是堵塞的。这意味着,当一个线程调用read() 或 write()时,该线程被堵塞,直到有一些数据被读取。或数据全然写入。该线程在此期间不能再干不论什么事情了。
Java NIO的非堵塞模式。使一个线程从某通道发送请求读取数据,可是它仅能得到眼下可用的数据,假设眼下没有数据可用时,就什么都不会获取。而不是保持线程堵塞。所以直至数据变的能够读取之前。该线程能够继续做其它的事情。非堵塞写也是如此。
一个线程请求写入一些数据到某通道,但不须要等待它全然写入,这个线程同一时候能够去做别的事情。线程通常将非堵塞IO的空暇时间用于在其它通道上运行IO操作,所以一个单独的线程如今能够管理多个输入和输出通道(channel)。
介质 <----> OS内核空间 <----> 应用程序空间 无论是非堵塞式读还是写,介质到OS内核这一段都不会堵塞调用程序,只是由于是同步(非异步)读取和写入,所以OS到应用程序这段还是须要同步堵塞的。
选择器(Selectors)
Java NIO的选择器同意一个单独的线程来监视多个输入通道。你能够注冊多个通道使用一个选择器。然后使用一个单独的线程来“选择”通道:这些通道里已经有能够处理的输入,或者选择已准备写入的通道。
这样的选择机制,使得一个单独的线程非常easy来管理多个通道。
Java NIO最关键的三个概念各自是通道。缓冲区和选择器:
一、通道(Channel)
Java NIO的通道相似流。但又有些不同:
n 通道是双向的,可读也可写,而流的读写是单向的。
n 通道能够异步地读写。
n 无论读写,通道仅仅能和Buffer交互。
JavaNIO中最重要的几个Channel的实现:
u FileChannel:从文件里读写数据(仅仅有堵塞模式)。
u DatagramChannel:通过UDP读写网络中的数据(堵塞和非堵塞可选)。
u SocketChannel:通过TCP读写网络中的数据(堵塞和非堵塞可选)。
u ServerSocketChannel:能够监听新进来的TCP连接,像Webserver那样。对每个新进来的连接都会创建一个SocketChannel。
以下是一个通过FileChannel来向文件里写入数据的样例:
public class Test { public static void main(String[] args) throws IOException { File file = new File("test.txt"); FileOutputStream os = new FileOutputStream(file); FileChannel channel = os.getChannel(); ByteBuffer buffer = ByteBuffer.allocate(1024); String str = "hello,jiyiqin"; buffer.put(str.getBytes()); buffer.flip(); channel.write(buffer); channel.close(); os.close(); } } 备注:上面演示样例有两个关键的地方:
(1)一个是通过FileOutputStream文件输出流获取通道。旧的IO类库(或者说面向流的IO类库)中FileInputStream/FileOutputStream和RandomAccessFile三个类被改动以能够产生FileChannel通道。可是面向字符的流Reader/Writer不能产生通道。
(2)另外在将缓冲区数据写入通道之前必须要调用缓冲区的flip方法转换为读模式,让通道可从缓冲区读取数据。
二、缓冲区(Buffer)
Java NIO中的Buffer用于和NIO通道进行交互。数据是从通道读入缓冲区或从缓冲区写入到通道中。
当向buffer写入数据时,buffer会记录下写了多少数据。
一旦要读取数据。须要通过flip()方法将Buffer从写模式切换到读模式。
在读模式下,能够读取之前写入到buffer的全部数据。一旦读完了全部的数据,就须要清空缓冲区,让它能够再次被写入。有两种方式能清空缓冲区:调用clear()或compact()方法。clear()方法会清空整个缓冲区。
compact()方法仅仅会清除已经读过的数据。不论什么未读的数据都被移到缓冲区的起始处,新写入的数据将放到缓冲区未读数据的后面。
缓冲区本质上是一块能够写入数据。然后能够从中读取数据的内存。这块内存被包装成NIO Buffer对象,并提供了一组方法,用来方便的訪问该块内存。
以下是一个从文件通道FileChannel读取数据的样例:
RandomAccessFile aFile = newRandomAccessFile("data/nio-data.txt", "rw"); FileChannel inChannel =aFile.getChannel(); ByteBuffer buf = ByteBuffer.allocate(48); int bytesRead = inChannel.read(buf);while (bytesRead != -1) { buf.flip(); //使缓冲区可读 while(buf.hasRemaining()){ System.out.print((char)buf.get()); //一次读取一字节 } buf.clear(); bytesRead= inChannel.read(buf);}aFile.close();
三、选择器(Selector)
Selector同意单线程处理多个Channel。
假设你的应用打开了多个连接(通道)。但每个连接的流量都非常低,使用Selector就会非常方便。比如。在一个聊天server中。
仅用单个线程来处理多个Channels的优点是,仅仅须要更少的线程来处理通道。其实,能够仅仅用一个线程处理全部的通道。对于操作系统来说,线程之间上下文切换的开销非常大,并且每个线程都要占用系统的一些资源(如内存)。
因此,使用的线程越少越好。
可是。须要记住,现代的操作系统和CPU在多任务方面表现的越来越好,所以多线程的开销随着时间的推移,变得越来越小了。
实际上。假设一个CPU有多个内核。不使用多任务可能是在浪费CPU能力。无论怎么说,关于那种设计的讨论应该放在还有一篇不同的文章中。在这里。仅仅要知道使用Selector能够处理多个通道就足够了。
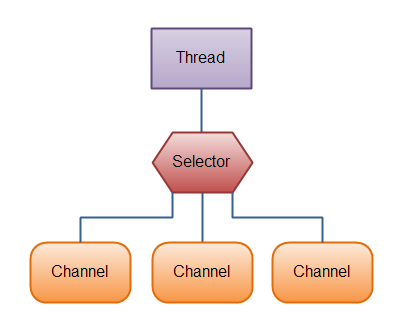
下图用一张转载的图展示在一个单线程中使用一个Selector处理3个Channel:
步骤1:Selector的创建
通过调用Selector.open()方法创建一个Selector,例如以下:
Selectorselector = Selector.open();
步骤2:向Selector注冊通道
为了将Channel和Selector配合使用,实现单个线程处理多个通道的梦想,必须将channel注冊到selector上。
能够通过SelectableChannel.register()方法来实现,例如以下:
channel.configureBlocking(false); SelectionKey key= channel.register(selector, Selectionkey.OP_READ);
当中第一句代码设置通道为非堵塞模式。然后第二句向selector注冊该通道。register()方法的第二个參数。这是一个“interest集合”,意思是在通过Selector监听Channel时对什么事件感兴趣。能够监听四种不同类型的事件:
SelectionKey.OP_CONNECT
SelectionKey.OP_ACCEPT
SelectionKey.OP_READ
SelectionKey.OP_WRITE
特别注意:与Selector一起使用时,Channel必须处于非堵塞模式下。
这意味着不能将FileChannel与Selector一起使用,由于FileChannel不能切换到非堵塞模式(由于其本身特性。要注意这里指的文件和Linux中的文件不同,Linux中的文件能够是代表磁盘文件、打印机设备、网卡等,而这里说的文件就仅仅是磁盘文件)。
而套接字通道都能够。
步骤3:堵塞监视通道
一旦向Selector注冊了一或多个通道,就能够调用几个重载的select()方法。这些方法返回你所感兴趣的事件(如连接、接受、读或写)已经准备就绪的那些通道。换句话说。假设你对“读就绪”的通道感兴趣,select()方法会返回读事件已经就绪的那些通道。
以下是select()方法:
int select()int select(long timeout)int selectNow()
select()堵塞到至少有一个通道在你注冊的事件上就绪了。
select(long timeout)和select()一样,除了最长会堵塞timeout毫秒(參数)。
selectNow()不会堵塞。无论什么通道就绪都立马返回(译者注:此方法运行非堵塞的选择操作。
假设自从前一次选择操作后,没有通道变成可选择的,则此方法直接返回零。)。
步骤4:遍历selectedKeys()訪问就绪通道
一旦调用了select()方法。并且返回值表明有一个或很多其它个通道就绪了,然后能够通过调用selector的selectedKeys()方法,訪问“已选择键集(selected key set)”中的就绪通道。例如以下所看到的:
Set selectedKeys =selector.selectedKeys();
能够遍历这个已选择的键集合来訪问就绪的通道。
以下给出一个完整的Channel和Selector结合的样例:
Selector selector = Selector.open(); channel.configureBlocking(false); //配置Channel为非堵塞SelectionKey key =channel.register(selector, SelectionKey.OP_READ); //用selector注冊该通道上的读事件while(true) { intreadyChannels = selector.select(); //開始监听通道 if(readyChannels == 0) continue; SetselectedKeys = selector.selectedKeys(); Iterator keyIterator = selectedKeys.iterator(); while(keyIterator.hasNext()) { //轮训通道事件类型,进行相应处理 SelectionKey key = keyIterator.next(); if(key.isAcceptable()) { // a connection was accepted by a ServerSocketChannel. }else if (key.isConnectable()) { // a connection was established with a remote server. }else if (key.isReadable()) { // a channel is ready for reading }else if (key.isWritable()) { // a channel is ready for writing } } } NIO = 选择器 + 非堵塞模式的套接字通道
套接字通道包括:SocketChannel、ServerSocketChannel和DatagramChannel。
SocketChannel是一个连接到TCP网络套接字的通道。能够通过2种方式创建:
1) 打开一个SocketChannel并连接到互联网上的某台server。
2) 一个新连接到达ServerSocketChannel时创建一个SocketChannel。
ServerSocketChannel通过ServerSocketChannel.accept() 方法监听新进来的连接。当 accept()方法返回的时候,它返回一个包括新进来的连接的 SocketChannel。因此。accept()方法会一直堵塞到有新连接到达。DatagramChannel是一个能收发UDP包的通道。由于UDP是无连接的网络协议。所以不能像其它通道那样读取和写入。它发送和接收的是数据包。
将套接字通道和Selector结合,由于选择器的多路复用特性(事件驱动)和套接字通道的非堵塞特性。可有效地解决高并发环境下对于client请求处理会耗费大量线程资源的情况。
(1)传统的同步堵塞式IO(网络套接字编程Socket):针对client的每个请求的连接,都须要分配一个单独的线程进行处理。由于要随时监视其是否有数据读写,并且在数据读写操作时,由于是堵塞式的。所以即使没有数据到来,也会一直堵塞等待。这显然会浪费大量CPU和线程资源。
(2)而多路复用的选择器和非堵塞式的套接字通道的结合:不但能够用一个线程来监视多个与client建立的网络连接,还能够在读写数据时。一旦数据没有准备好。就立马返回而不会堵塞(虽然实际上一旦运行读写是一般数据都已经准备好)。所以在并发较高的场景下,这样的方式大大节约了CPU和线程(内存)资源。
具体能够參考我文章。
本文转自mfrbuaa博客园博客,原文链接:http://www.cnblogs.com/mfrbuaa/p/5415482.html,如需转载请自行联系原作者